{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




by Krishna Sankar
Standard relational data access is very important for Java programs because the Java applets by nature are not monolithic, all-consuming applications. As applets by nature are modular, they need to read persistent data from data stores, process the data, and write the data back to data stores for other applets to process. Monolithic programs could afford to have their own proprietary schemes of data handling. But as Java applets cross operating system and network boundaries, you need published open data access schemes.
The Java Database Connectivity (JDBC) of the Java Enterprise API's JavaSoft is the first of such cross-platform, cross-database approaches to database access from Java programs. From a developer's point of view, JDBC is the first standardized effort to integrate relational databases with Java programs. JDBC has opened all the relational power that can be mustered to Java applets and applications. In this chapter, you will see how JDBC can be effectively used to develop database programs using Java.
First, you will look at some basics applicable to databases in general.
Databases, as you know, contain organized data. A database can be as simple as a flat file (a single computer file with data usually in a tabular form) containing names and telephone numbers of one's friends, or as elaborate as the worldwide reservation system of a major airline. Many of the principles discussed in this chapter are applicable to a wide variety of database systems.
Structurally, there are three major types of databases:
During the 1970s and 1980s, the hierarchical scheme was very popular. This scheme treats data as a tree-structured system with data records forming the leaves. Examples of the hierarchical implementations are schemes like b-tree and multi-tree data access. In the hierarchical scheme, to get to data, users need to traverse up and down the tree structure. The most common relationship in a hierarchical structure is a one-to-many relationship between the data records, and it is difficult to implement a many-to-many relationship without data redundancy.
The network data model solved this problem by assuming a multi-relationship between data elements. In contrast to the hierarchical scheme where there is a parent-child relationship, in the network scheme, there is a peer-to-peer relationship. Most of the programs developed during those days used a combination of the hierarchical and network data storage and access model.
During the 90s, the relational data access scheme came to the forefront. The relational scheme views data as rows of information. Each row contains columns of data, called fields. The main concept in the relational scheme is that the data is uniform. Each row contains the same number of columns. One such collection of rows and columns is called a table. Many such tables (which can be structurally different) form a relational database.
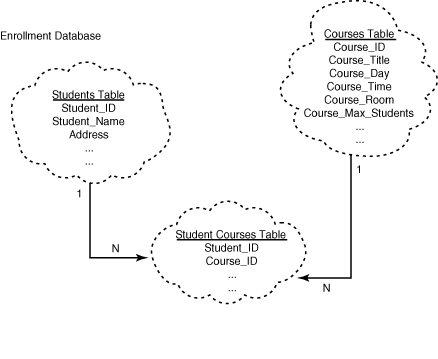
Figure 15.1 shows a sample relational database schema (or table layout) for an enrollment database. In this example, the database consists of three tables: the Students Table that contains student information, the Courses Table that has the courses information, and the StudentCourses Table that has the student course relation. The Students Table has student ID, name, address, and so on; the Courses Table contains the course ID, subject name or course title, term offered, location, and so on.
Figure 15.1 : A sample relational database schema for the Enrollment Database.
Now that you have the student and course tables of data, how do you relate the tables? That is where the relational part of the relational database comes in the picture. To relate two tables, either the two tables will have a common column, or you will need to create a third table with two columns, one from the first table and the second from the second table.
Take a look at how this is done. In this example, to relate the Students Table with the Courses Table, you need to make a new StudentCourses Table which has two columns: Student_ID and Course_ID. Whenever a student takes a course, make a row in the StudentCourses Table with the Student_ID and the Course_ID. Thus, the table has the student and course relationship. If you want to find a list of students and the subjects they take, go to the Student Courses Table, read each row, find the student name corresponding to the Student_ID, from the Courses Table find the course title corresponding to the Course_ID, and select the Student_Name and the Course_Title columns.
Once relational databases started becoming popular, database experts wanted a universal database language to perform actions on data. The answer was SQL, or Structured Query Language. The SQL existed before the relational concepts but the association of SQL and relational database concepts made SQL grow into a mainstream database language.SQL has constructs for:
data handling and interaction with the back-end database management
system.
| Tip |
Each database vendor has their own implementation of the SQL. In the Microsoft SQL server,which is one of the client/server relational DMBS, the SQL is called the Transact/SQL, while the Oracle SQL is called the PL/SQL. The different vendors have different extensions to the common X/Open and ANSI X3H2 standard. For the most part, SQL = SQL on any platform. The differences come in framework additions designed to take advantage of a particular database's functionality or capabilities. |
| Note |
SQL became an ANSI (American National Standards Institute) standard in 1986 and later was revised to become SQL-92. JDBC is SQL-92-compliant. |
Just because a database consists of tables with rows of data does not mean that you are limited to view the data in the fixed tables in the database. A join is a process in which two or more tables are combined to form a single table. The join can be dynamic, where two tables are merged to form a virtual table, or static, where two tables are joined and saved for future reference. A static join is usually a stored procedure which can be invoked to refresh and then query the saved table. Joins are performed on tables that have a column of common information. Conceptually, there are many types of joins, which are discussed later in this section.
Before you dive deeper into joins, look at the following example,
where you fill the tables of the database schema in Figure 15.1
with a few records as shown in Tables 15.1, 15.2, and 15.3. In
these tables, I show only the relevant fields or columns.
A simple join called the inner join with the Students and StudentCourses
Tables will give you a table like the one shown in Table 15.4.
That is, you get a new table which combines the Students and StudentCourses
Tables by adding the Student_Namecolumn to the StudentCourses
Table.
Just because you are using the Student_ID to link the two tables does not mean that you should fetch that column. You can exclude the key field from the result table of an inner join. The SQL statement for this inner join is as follows:
SELECT Students.Student_Name, StudentCourses.Course_ID FROM Students, StudentCourses WHERE Students.Student_ID = StudentCourses.Student_ID
An outer join between two tables (say Table1 and Table2) occurs
when the result table has all the rows of the first table and
the common records of the second table. (The first and second
table are determined by the order in the SQL statement.) If you
assume a SQL statement with the "FROM Table1,Table2"
clause, in a left outer join, all rows of the first table (Table1)
and common rows of the second table (Table2) are selected. In
a right outer join, all records of the second table (Table2) and
common rows of the first table (Table1) are selected. A left outer
join with the Students Table and the StudentCourses Table creates
Table 15.5.
This join is useful if you want the names of all students, regardless of whether they are taking any subjects this term, and the subjects taken by the students who have enrolled in this term. Some people call it an if-any join, as in, "Give me a list of all students and the subjects they are taking, if any."
The SQL statement for this outer join is as follows: (oj = Outer Join)
SELECT Students.Student_ID,Students.Student_Name,StudentCourses.Course_ID
FROM {
oj c:\enrol.mdb Students
LEFT OUTER JOIN c:\enrol.mdb
StudentCourses ON Students.Student_ID = StudentCourses .Student_ID
}
The full outer join, as you may have guessed, returns all the
records from both the tables merging the common rows, as shown
in Table 15.6.
What if you want only the students who haven't enrolled in this term or the subjects who have no students (the tough subjects or professors)? Then, you resort to the subtract join. In this case, the join returns the rows that are not in the second table. Remember, a subtract join has only the fields from the first table. By definition, there are no records in the second table. The SQL statement looks like the following:
SELECT Students.Student_Name
FROM {
oj c:\enrol.mdb Students
LEFT OUTER JOIN c:\enrol.mdb
StudentCourses ON Students.Student_ID = StudentCourses .Student_ID
}
WHERE (StudentCourses.Course_ID Is Null)
There are many other types of joins, such as the self join, which is a left outer join of two tables with the same structure. An example is the assembly/parts explosion in a Bill of Materials application for manufacturing. But usually the join types that we have discussed so far are enough for normal applications. As you gain more expertise in SQL statements, you will start developing exotic joins.
In all of these joins, you were comparing columns that have the same values; these joins are called equi-joins. Joins are not restricted to comparing columns of equal values. You can join two tables based on column value conditions (such as the column of one table being greater than the other).
One more point: For equi-joins, as the column values are equal, you retrieved only one copy of the common column. Then, the joins are called natural joins. When you have a non equi-join, you might need to retrieve the common columns from both tables.
Once a SQL statement reaches a database management system, the DBMS parses the SQL statement and translates the SQL statements to an internal scheme called a query plan to retrieve data from the database tables. This internal scheme generator, in all the client/server databases, includes an optimizer module. This module, which is specific to a database, knows the limitations and advantages of the database implementation.
In many databases-for example, the Microsoft SQL Server-the optimizer is a cost-based query optimizer. When given a query, this optimizer generates multiple query plans, computes the cost estimates for each (knowing the data storage schemes, page I/O, and so on), and then determines the most efficient access method for retrieving the data, including table join order and index usage. This optimized query is converted into a binary form called the execution plan, which is executed against the data to get the result. There are known cases where straight queries take hours to perform that when run through an optimizer have resulted in an optimized query, which is performed in minutes. All the major client/server databases have the query optimizer module built in, which processes all the queries. A database system administrator can assign values to parameters such as cost, storage scheme, and so on, and fine-tune the optimizer.
A typical client/server system is at least a department-wide system, and most likely an organizational system spanning many departments in an organization. Mission-critical and line-of-business systems, such as brokerage, banking, manufacturing, and reservation systems, fall into this category. Most systems are internal to an organization, and also span the customers and suppliers. Almost all such systems are on a local area network (LAN), plus they have wide area network (WAN) connections and dial-in capabilities. With the advent of the Internet/intranet and Java, these systems are getting more and more sophisticated and are capable of doing business in many new ways.
Take the case of Federal Express. Their Web site can now schedule package pickups, track a package from pickup to delivery, and get delivery information and time. You are now on the threshold of an era where online commerce will be as common as shopping malls. Now, look at some of the concepts that drive these kinds of systems.
Most of the application systems will involve modules with functions
for a front-end GUI, business rules processing, and data access
through a DBMS. In fact, major systems like online reservation,
banking and brokerage, and utility billing involve thousands of
business rules, heterogeneous databases spanning the globe, and
hundreds of GUI systems. The development, administration, maintenance,
and enhancement of these systems involve handling millions of
lines of code, multiple departments, and coordinating the work
of hundreds if not thousands of personnel across the globe. The
multi-tier system design and development concepts are applied
to a range of systems from departmental systems to such global
information systems.
| Tip |
In the two- and three-tier systems, an application is logically divided into three parts:
|
On the basic level, a two-tier system involves the GUI and business logic, directly accessing the database. The GUI can be on a client system, and the database can be on the client system or on a server. Usually, the GUI is written in languages like C++, Visual Basic, PowerBuilder, Access Basic, and Lotus Script. The database systems typically are Microsoft Access, Lotus Approach, Sybase "SQL Anywhere," or Watcom DB Engine and Personal Oracle.
Most of the organizational and many of the departmental client/server applications today follow the three-tier strategy, where the GUI, business logic, and the DBMS are in logically three layers. Here, the GUI development tools are Visual Basic, C++, and PowerBuilder. The middle-tier development tools also tend to be C++ or Visual Basic, and the back-end databases are Oracle, Microsoft SQL Server, or Sybase SQL Server. The three-tier concept gave rise to an era of database servers, application servers, and GUI client machines. Operating systems such as UNIX, Windows NT, and Solaris rule the application server and database server world. Client operating systems like Windows are popular for the GUI front end.
Now with Internet and Java, the era of "network is the computer" and "thin client" paradigm shifts have begun. The Java applets with their own objects and methods created the idea of the multi-tiered client/server systems. Theoretically, a Java applet can be a business rule, GUI, or DBMS interface. Each applet can be considered a layer. In fact, the Internet and Java were not the first to introduce the object-oriented, multi-tiered systems concept. OMG's CORBA architecture and Microsoft's OLE (now ActiveX) architectures are all proponents of modular object-oriented, multi-platform systems. With Java and the Internet, these concepts became much easier to implement.
In short, the systems' design and implementation progressed from two-tiered architecture to three-tiered architecture to the current inter-networked, Java applet-driven multi-tier architecture.
The concept of transactions is an integral part of any client/server
database. A transaction is a group of SQL statements that
update, add, and delete rows and fields in a database. Transactions
have an all or nothing property-either they are committed if all
statements are successful, or the whole transaction is rolled
back if any of the statements cannot be executed successfully.
Transaction processing assures the data integrity and data consistency
in a database.
| Note |
JDBC supports transaction processing with the commit() and rollback() methods. Also, JDBC has the autocommit() which, when on, all changes are committed automatically and, if off, the Java program has to use the commit() or rollback() methods to effect the changes to the data. |
The characteristics of a transaction are described in terms of the Atomicity, Consistency, Isolation, and Durability (ACID) properties.
A transaction is atomic in the sense that it is an entity. All the components of a transaction happen or do not happen. There is no partial transaction. If only a partial transaction can happen, then the transaction is aborted. The atomicity is achieved by the commit() or rollback() methods.
A transaction is consistent because it does not perform any actions that violate the business logic or relationships between data elements. The consistent property of a transaction is very important when you develop a client/server system, because there will be many transactions to a data store from different systems and objects. If a transaction leaves the data store inconsistent, all other transactions also would potentially be wrong, resulting in a system-wide crash or data corruption.
A transaction is isolated because the results of a transaction are self-contained. They do not depend on any preceding or succeeding transaction. This is related to a property called serializability, which means the sequence of transactions are independent; in other words, a transaction does not assume any external sequence.
Finally, a transaction is durable, meaning the effects of a transaction are permanent even in the face of a system failure. That means some form of permanent storage should be a part of a transaction.
A related topic in transactions is the coordination of transactions across heterogeneous data sources, systems, and objects. When the transactions are carried out in one relational database, you can use the commit(), rollback(), beginTransaction(), and endTransaction() statements to coordinate the process. But what if you have diversified systems participating in a transaction? How do you handle such a system? As an example, look at the Distributed Transaction Coordinator (DTC) available as a part of Microsoft SQL Server 6.5 database system.
In the Microsoft DTC, a transaction manager facilitates the coordination. Resource managers are clients that implement resources to be protected by transactions-for example, relational databases and ODBC data sources.
An application begins a transaction with the transaction manager, and then starts transactions with the resource managers, registering the steps (enlisting) with the transaction manager.
The transaction manager keeps track of all enlisted transactions. The application, at the end of the multi-data source transaction steps, calls the transaction manager to either commit or abort the transaction.
When an application issues a commit command to the transaction manager, the DTC performs a two-phase commit protocol:
The Microsoft DTC is an example of very powerful next generation transaction coordinators from the database vendors. As more and more multi-platform, object-oriented Java systems are being developed, this type of transaction coordinators will gain importance. Already, many middleware vendors are developing Java-oriented transaction systems.
A relational database query normally returns many rows of data. But an application program usually deals with one row at a time. Even when an application can handle more than one row-for example, by displaying the data in a table or spreadsheet format-it can still handle only a limited number of rows. Also, updating, modifying, deleting, or adding data is done on a row basis.
This is where the concept of cursors come in the picture. In this
context, a cursor is a pointer to a row. It is like the cursor
on the CRT-a location indicator.
| Note |
Different types of multi-user applications need different types of data sets in terms of data concurrency. Some applications need to know as soon as the data in the underlying database is changed. Such as the case with reservation systems, the dynamic nature of the seat allocation information is extremely important. Others such as statistical reporting systems need stable data; if data is in constant change, these programs cannot effectively display any results. The different cursor designs support the need for the various types of applications. |
A cursor can be viewed as the underlying data buffer. A fully
scrollable cursor is one where the program can move forward and
backward on the rows in the data buffer. If the program can update
the data in the cursor, it is called a scrollable, updatable
cursor.
| Caution |
An important point to remember when you think about cursors is the transaction isolation. If a user is updating a row, other users might be viewing the row in a cursor of their own. Data consistency is important here. Worse, the other users also might be updating the same row! |
| Tip |
The ResultSet in JDBC API is a cursor. But it is only a forward scrollable cursor-this means you can move only forward using the getNext() method. |
ODBC cursors are very powerful in terms of updatability, concurrency, data integrity, and functionality. The ODBC cursor scheme allows positioned delete and update and multiple row fetch (called a rowset) with protection against lost updates.
ODBC supports static, keyset-driven, and dynamic cursors.
In the static cursor scheme, the data is read from the database once, and the data is in the snapshot recordset form. Because the data is a snapshot (a static view of the data at a point of time), the changes made to the data in the data source by other users are not visible. The dynamic cursor solves this problem by keeping live data, but this takes a toll on network traffic and application performance.
The keyset-driven cursor is the middle ground where the rows are
identified at the time of fetch, and thus changes to the data
can be tracked. Keyset-driven cursors are useful when you implement
a backward scrollable cursor. In a keyset-driven cursor, additions
and deletions of entire rows are not visible until a refresh.
When you do a backward scroll, the driver fetches the newer row
if any changes are made.
| Note |
ODBC also supports a modified scheme, where only a small window of the keyset is fetched, called the mixed cursor, which exhibits the keyset cursor for the data window and a dynamic cursor for the rest of the data. In other words, the data in the data window (called a RowSet) is keyset-driven, and when you access data outside the window, the dynamic scheme is used to fetch another keyset-driven buffer. |
You might be wondering where these cursor schemes are applied and why we need such elaborate schemes. In short, all the cursor schemes have their place in information systems.
Static cursors provide a stable view of the data, because the data does not change. They are good for data mining and data warehousing types of systems. For these applications, you want the data to be stable for reporting executive information systems or for statistical or analysis purposes. Also, the static cursor outperforms other schemes for large amounts of data retrieval.
On the other hand, for online ordering systems or reservation systems, you need a dynamic view of the system with row locks and views of data as changes are made by other users. In such cases, you will use the dynamic cursor. In many of these applications, the data transfer is small, and the data access is performed on a row-by-row basis. For these online applications, aggregate data access is very rare.
Bookmark is a concept related to the cursor model, but is independent of the cursor scheme used. Bookmark is a placeholder for a data row in a table. The application program requests a bookmark for a row from the underlying database management system. The DBMS usually returns a 32-bit marker which can be later used by the application program to get to that row of data. In ODBC, you will use the SQLExtendedFetch function with SQL_FETCH_BOOKMARK option to get a bookmark. The bookmark is useful for increasing performance of GUI applications, especially the ones where the data is viewed through a spreadsheet-like interface.
This is another cursor-related concept. If a cursor model supports positioned update/delete, then you can update/delete the current row in a result set without any more processing, such as a lock, read, or fetch.
In SQL, a positioned update or delete statement is in the form of:
UPDATE/DELETE <Field or Column values etc.> WHERE CURRENT OF <cursor name>
The positioned update statement to update the fields in the current row is
UPDATE <table> SET <field> = <value> WHERE CURRENT OF <cursor name>
The positioned delete statement to delete the current row takes the form of:
DELETE <table> WHERE CURRENT OF <cursor name>
Generally, for this type of SQL statement to work, the underlying driver or the DBMS has to support updatability, concurrency, and dynamic scrollable cursors. But there are many other ways of providing the positioned update/delete capability at the application program level. Presently, JDBC does not support any of the advanced cursor functionalities. However, as the JDBC driver development progresses, I am sure there will be very sophisticated cursor management methods available in the JDBC API.
Data replication is the distribution of corporate data to many locations across the organization, and it provides reliability, fault-tolerance, data-access performance due to reduced communication, and, in many cases, manageability as the data can be managed as subsets.
As you have seen, the client/server systems span an organization, possibly its clients and suppliers, most probably in a wide geographic locations. Systems spanning the entire globe are not uncommon when you're talking about mission-critical applications, especially in today's global business market. If all the data is concentrated in a central location, it would be almost impossible for the systems to effectively access data and offer high performance. Also, if data is centrally located, in the case of mission-critical systems, a single failure will bring the whole business down. Using replicated data across an organization at various geographic locations is a sound strategy.
Different vendors handle replication differently. For example, the Lotus Notes group-ware product uses a replication scheme where the databases are considered peers, and additions/updates/deletions are passed between the databases. Lotus Notes has replication formulas that can select subsets of data to be replicated based on various criteria.
The Microsoft SQL server, on the other hand, employs a publisher-subscriber scheme where a database or part of a database can be published to many subscribers. A database can be a publisher and a subscriber. For example, the western region can publish its slice of sales data while receiving (subscribing to) sales data from other regions.
There are many other replication schemes from various vendors to manage and decentralize data. Replication is a young technology that is slowly finding its way into many other products.
Now it is time for you to dive deep into the main topic, JDBC.
JDBC is Java Database Connectivity-a set of relational database
objects and methods for interacting with data sources. The JDBC
APIs are part of the Enterprise APIs specified by JavaSoft, and
thus they will be a part of all Java Virtual Machine (JVM) implementations.
| Tip |
Even though the objects and methods are based on the relational database model, JDBC makes no assumption about the underlying data source or the data storage scheme. You can access and retrieve audio or video data from many sources and load into Java objects using the JDBC APIs! The only requirement is that there should be a JDBC implementation for that source. |
JavaSoft introduced the JDBC API specification in March 1996 as draft Version 0.50 and was open for public review. The specification went from Version 0.50 to 0.60 to 0.70 and now is at Version 1.01, dated August 8, 1996. The JDBC Version 1.01 specification available at http://splash.javasoft.com/jdbc/ (jdbc-0101.ps or jdbc-0101.pdf) includes all of the improvements from the four months of review by vendors, developers, and the general public. Most probably, by the time you are reading this chapter, JDBC Version 1.1 or even 2.0 might be available !
Now, look at the origin and design philosophies. The JDBC designers based the API on X/Open SQL Call Level Interface (CLI). It is not coincidental that ODBC is also based on the X/Open CLI. The JavaSoft engineers wanted to gain leverage from the existing ODBC implementation and development expertise, thus making it easier for Independent Software Vendors (ISVs) and system developers to adopt JDBC. But ODBC is a C interface to DBMSs and thus is not readily convertible to Java. So JDBC design followed ODBC in spirit as well in its major abstractions and implemented the SQL CLI with "a Java interface that is consistent with the rest of the Java system," as it is described in Section 2.4 of the JDBC specification. For example, instead of the ODBC SQLBindColumn and SQLFetch to get column values from the result, JDBC used a simpler approach (which you see later).
As we have discussed, JDBC is designed upon the CLI model. JDBC defines a set of API objects and methods to interact with the underlying database. A Java program first opens a connection to a database, makes a statement object, passes SQL statements to the underlying DBMS through the statement object, and retrieves the results as well as information about the result sets. Typically, the JDBC class files and the Java applet/application reside in the client. They could be downloaded from the network also. To minimize the latency during execution, it is better to have the JDBC classes in the client. The Database Management System and the data source are typically located in a remote server.
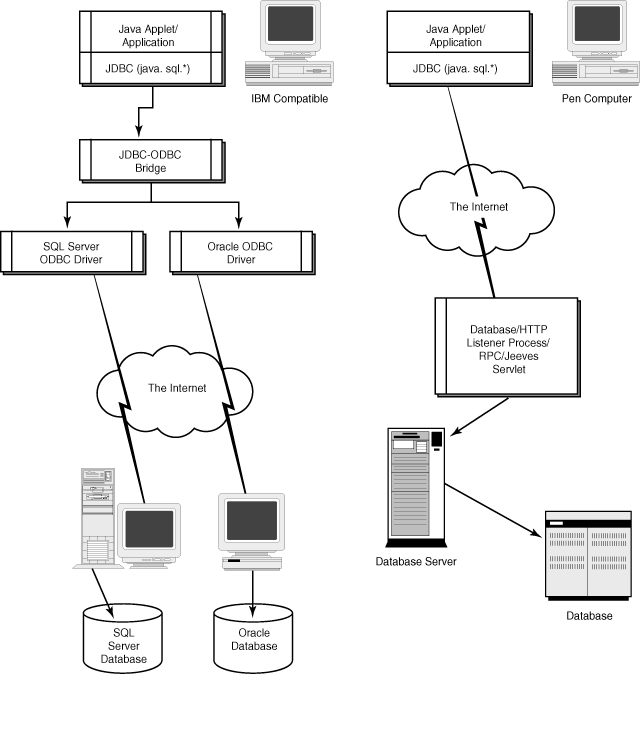
Figure 15.2 shows the JDBC communication layer alternatives. The applet/application and the JDBC layers communicate in the client system, and the driver takes care of interacting with the database over the network.
The JDBC classes are in the java.sql package, and all Java programs
use the objects and methods in the java.sql package to read from
and write to data sources. A program using the JDBC will need
a driver for the data source with which it wants to interface.
This driver can be a native module (like the JDBCODBC.DLL for
the Windows JDBC-ODBC Bridge developed by Sun/Intersolv), or it
can be a Java program that talks to a server in the network using
some RPC or Jeeves Servlet or an HTTP talker-listener protocol.
Both schemes are shown in Figure 15.2.
| Note |
As you can see from Figure 15.2, JDBC can be implemented as a native driver or as a gateway to an RPC. Which implementation is better is a question that will be answered as the JDBC architecture matures. One reason to implement a native library is the advantage of speed. Also, local databases could be handled using native libraries more easily than gateways. On the other hand, for a handheld device or a network computer, "network is the system." For these devices, a full Java implementation of JDBC that talks to an RPC type of system or a Jeeves servlet on the database server is a good solution. |
It is conceivable that an application will deal with more than
one data source-possibly heterogeneous data sources. (A database
gateway program is a good example of an application that accesses
multiple heterogeneous data sources.) For this reason, JDBC has
a DriverManager whose function is to manage the drivers and provide
a list of currently loaded drivers to the application programs.
| Note |
Even though the word Database is in the name JDBC, the form, content, and location of the data is immaterial to the Java program using JDBC, so long as there is a driver for that data. Hence, the notation data source to describe the data is more accurate than Database, DBMS, DB, or just file. In the future, Java devices such as televisions, answering machines, or network computers will access, retrieve, and manipulate different types of data (audio, video, graphics, time series, and so on) from various sources that are not relational databases at all! And much of the data might not even come from mass storage. For example, the data could be video stream from a satellite or audio stream from a telephone. ODBC also refers to data sources, rather than databases when being described in general terms. |
Security is always an important issue, especially when databases
are involved. As of the writing of this book, JDBC follows the
standard security model in which applets can connect only to the
server from where they are loaded; remote applets cannot connect
to local databases. Applications have no connection restrictions.
For pure Java drivers, the security check is automatic, but for
drivers developed in native methods, the drivers must have some
security checks.
| Note |
With Java 1.1 and the Java Security API, you will have the ability to establish "trust relationships," which will allow you to verify trusted sites. Then, you could give applets downloaded from trusted sources more functionality by giving them access to local resources. |
As a part of JDBC, JavaSoft also will deliver a driver to access ODBC data sources from JDBC. This driver is jointly developed with Intersolv and is called the JDBC-ODBC bridge. The JDBC-ODBC bridge is implemented as the JdbcOdbc.class and a native library to access the ODBC driver. For the Windows platform, the native library is a DLL (JDBCODBC.DLL).
As JDBC is close to ODBC in design, the ODBC bridge is a thin layer over JDBC. Internally, this driver maps JDBC methods to ODBC calls, and thus interacts with any available ODBC driver. The advantage of this bridge is that now JDBC has the capability to access almost all databases, as ODBC drivers are widely available. You can use this bridge (Version 1.0105) to run the example programs in this chapter.
When you look at the class hierarchy and methods associated with
it, the topmost class in the hierarchy is the DriverManager.
The DriverManager keeps the
driver infor-mation, state information, and so on. When each driver
is loaded, it registers with the DriverManager.
The DriverManager, when required
to open a connection, selects the driver depending on the JDBC
URL.
| Note |
True to the nature of the Internet, JDBC identifies a database with an URL. The URL is of the form: jdbc:<subprotocol>:<subname related to the DBMS/Protocol> For databases on the Internet/intranet, the subname can contain the Net URL //hostname:port/… The <subprotocol> can be any name that a database understands. The odbc subprotocol name is reserved for ODBC-style data sources. A normal ODBC database JDBC URL looks like: jdbc:odbc:<>;User=<>;PW=<> If you are developing a JDBC driver with a new subprotocol, it is better to reserve the subprotocol name with JavaSoft, which maintains an informal subprotocol registry. |
The java.sql.Driver class is usually referred to for information such as PropertyInfo, version number, and so on. So the class could be loaded many times during the execution of a Java program using the JDBC API.
Looking at the java.sql.Driver and java.sql.DriverManager classes and methods, as listed in Table 15.9, you see that the DriverManager returns a Connection object when you use the getConnection() method.
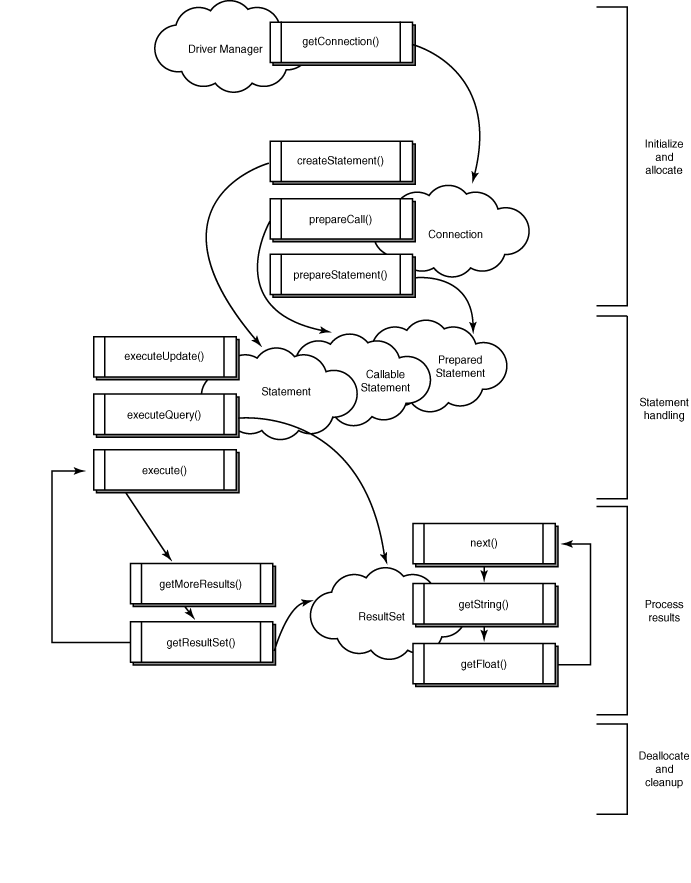
Other useful methods include the registerDriver(), deRegister(), and getDrivers() methods. Using the getDrivers() method, you can get a list of registered drivers. Figure 15.3 shows the JDBC class hierarchy, as well as the flow of a typical Java program using the JDBC APIs.
Figure 15.3 : JDBC class hierarchy and a JDBC API flow.
In the next subsection, follow the steps required to access a simple database access using JDBC and the JDBC-ODBC driver.
To handle data from a database, a Java program implements the following general steps. Figure 15.3 shows the general JDBC objects, the methods, and the sequence. First, the program calls the getConnection() method to get the Connection object. Then, it creates the Statement object and prepares a SQL statement.
A SQL statement can be executed immediately (Statement object), or can be a compiled statement (PreparedStatement object) or a call to a stored procedure (CallableStatement object). When the method executeQuery() is executed, a ResultSet object is returned. SQL statements such as update or delete will not return a ResultSet. For such statements, the executeUpdate() method is used. The ex
ecuteUpdate() method returns an integer which denotes the number of rows affected by the SQL statement.
The ResultSet contains rows of data that is parsed using the next() method. In case of a transaction processing application, methods such as rollback() and commit() can be used either to undo the changes made by the SQL statements or permanently affect the changes made by the SQL statements.
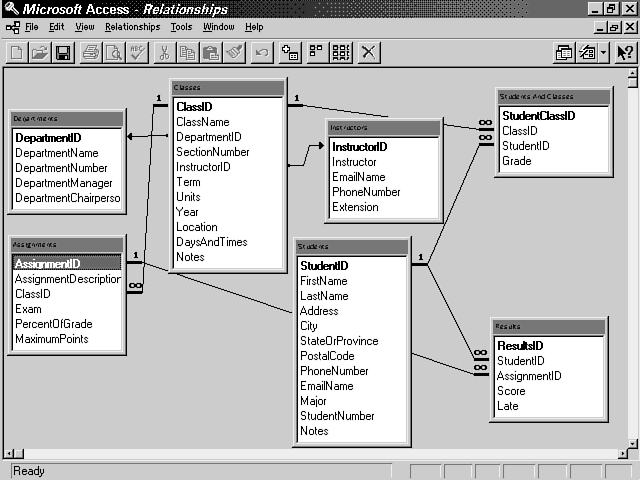
These examples access the Student database, the schema of which is shown in Figure 15.4. The tables in the examples that you are interested in are the Students Table, Classes Table, Instructors Table, and Students_Classes Table. This database is a Microsoft Access database. The full database and sample data are generated by the Access Database Wizard. You access the database using JDBC and the JDBC-ODBC bridge.
Figure 15.4 : JDBC example database schema.
Before you jump into writing a Java JDBC program, you need to configure an ODBC data source. As you saw earlier, the getConnection() method requires a data source name (DSN), user ID, and password for the ODBC data source. The database driver type or subprotocol name is odbc. So the driver manager finds out from the ODBC driver the rest of the details.
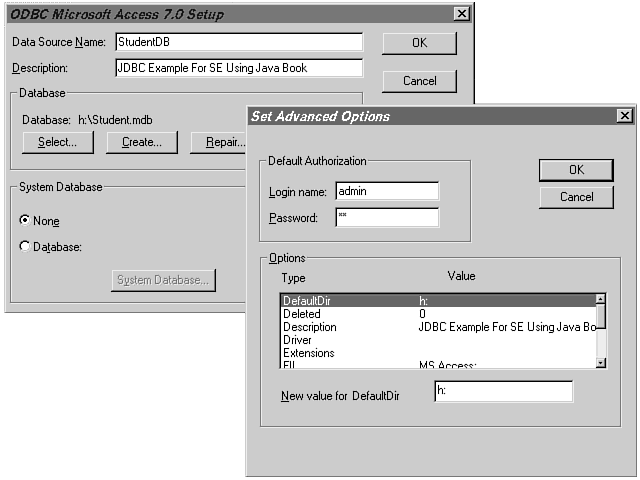
But wait, where do you put the rest of the details? This is where the ODBC setup comes into the picture. The ODBC Setup program runs outside the Java application from the Microsoft ODBC program group. The ODBC Setup program allows you to set up the data source so that this information is available to the ODBC Driver Manager, which, in turn, loads the Microsoft Access ODBC driver. If the database is in another DBMS form-say, Oracle-you configure this source as Oracle ODBC driver. In Windows 3.x, the Setup program puts this information in the ODBC.INI file. With Windows 95 and Windows NT 4.0, this information is in the Registry. Figure 15.5 shows the ODBC setup screen.
In Listing 15.1, you will list all of the students in the database by a SQL SELECT statement. The steps required to accomplish this task using the JDBC API are iterated as follows. For each step, the Java program code with the JDBC API calls follows the description of the steps.
Listing 15.1 Using a SQL SELECT Statement
//Declare a method and some variables.
public void ListStudents() throws SQLException {
int i, NoOfColumns;
String StNo,StFName,StLName;
//Initialize and load the JDBC-ODBC driver.
Class.forName ("jdbc.odbc.JdbcOdbcDriver");
//Make the connection object.
Connection Ex1Con = DriverManager.getConnection( "jdbc:odbc:StudentDB;uid="admin";pw="sa");
//Create a simple Statement object.
Statement Ex1Stmt = Ex1Con.createStatement();
//Make a SQL string, pass it to the DBMS, and execute the SQL statement.
ResultSet Ex1rs = Ex1Stmt.executeQuery(
"SELECT StudentNumber, FirstName, LastName FROM Students");
//Process each row until there are no more rows.
// Displays the results on the console.
System.out.println("Student Number First Name Last Name");
while (Ex1rs.next()) {
// Get the column values into Java variables
StNo = Ex1rs.getString(1);
StFName = Ex1rs.getString(2);
StLName = Ex1rs.getString(3);
System.out.println(StNo,StFName,StLName);
}
}
The program illustrates the basic steps that are needed to access a table and lists some of the fields in the records.
In Listing 15.2, you update the FirstName field in the Students Table by knowing the student's StudentNumber. As in the last example, the code follows the description of the step.
Listing 15.2 Updating the FirstName Field
//Declare a method and some variables and parameters.
public void UpdateStudentName(String StFName, String StLName,
String StNo) throws SQLException {
int RetValue;
// Initialize and load the JDBC-ODBC driver.
Class.forName ("jdbc.odbc.JdbcOdbcDriver");
// Make the connection object.
Connection Ex1Con = DriverManager.getConnection( "jdbc:odbc:StudentDB;uid="admin";pw="sa");
// Create a simple Statement object.
Statement Ex1Stmt = Ex1Con.createStatement();
//Make a SQL string, pass it to the DBMS, and execute the SQL statement
String SQLBuffer = "UPDATE Students SET FirstName = "+
StFName+", LastName = "+StLName+
" WHERE StudentNumber = "+StNo
RetValue = Ex1Stmt.executeUpdate( SQLBuffer);
System.out.println("Updated " + RetValue + " rows in the Database.");
}
In this example, you execute the SQL statement and get the number of rows affected by the SQL statement back from the DBMS.
The previous two examples show how you can do simple yet powerful SQL manipulation of the underlying data using the JDBC API in a Java program. In the following sections, you examine each JDBC class in detail.
The Connection class is one of the major classes in JDBC. It packs a lot of functionality, ranging from transaction processing to creating statements, in one class.
As you saw earlier, the connection is for a specific database
that can be interacted with in a specific subprotocol. The Connection
object internally manages all aspects about a connection, and
the details are transparent to the program. Actually, the Connection
object is a pipeline into the underlying DBMS driver. The information
to be managed includes the data source identifier, the subprotocol,
the state information, the DBMS SQL execution plan ID or handle,
and any other contextual information needed to interact successfully
with the underlying DBMS.
| Note |
The data source identifier could be a port in the Internet database server that is identified by the //<server name>:port/... URL, just a data source name used by the ODBC driver, or a full path name to a database file in the local computer. For all you know, it could be a pointer to a data feed of the stock market prices from Wall Street! |
Another important function performed by the Connection
object is transaction management. The handling of transactions
depends on the state of an internal autocommit flag that is set
using the setAutoCommit()
method, and the state of this flag can be read using the getAutoCommit()
method. When the flag is true,
the transactions are automatically committed as soon as they are
completed. There is no need for any intervention or commands from
the Java application program. When the flag is false,
the system is in the manual mode. The Java program has the option
to commit the set of transactions that happened after the last
commit or to rollback the transactions using the commit()
and rollback() methods.
| Note |
JDBC also provides methods for setting the transaction isolation modularity. When you are developing multi-tiered applications, there will be multiple users performing concurrently interleaved transactions that are on the same database tables. A database driver has to employ sophisticated locking and data-buffering algorithms and mechanisms to implement the transaction isolation required for a large-scale JDBC application. This is more complex when there are multiple Java objects working on many databases that could be scattered across the globe! Only time will tell what special needs for transaction isolation there will be in the new Internet/intranet paradigm. |
Once you have a successful Connection object to a data source, you can interact with the data source in many ways. The most common approach from an application developer standpoint is the objects that handle the SQL statements.
The Statement object does
all of the work to interact with the Database Management System
in terms of SQL statements. You can create many Statement
objects from one Connection object.
Internally, the Statement
object would be storing the various data needed to interact with
a database, including state information, buffer handles, and so
on. But these are transparent to the JDBC application program.
| Note |
When a program attempts an operation that is not in sync with the internal state of the system (for example, a next() method to get a row when no SQL statements have been executed), this discrepancy is caught and an exception is raised. This exception, normally, is probed by the application program using the methods in the SQLException object. |
JDBC supports three types of statements:
The Connection object has the createStatement(), prepareStatement(), and prepareCall() methods to create these Statement objects.
Before you explore these different statements, see the steps that a SQL statement goes through.
A Java application program first builds the SQL statement in a string buffer and passes this buffer to the underlying DBMS through some API call. A SQL statement needs to be verified syntactically, optimized, and converted to an executable form before execution. In the Call Level Interface (CLI) Application Program Interface (API) model, the application program passes the SQL statement to the driver which, in turn, passes it to the underlying DBMS. The DBMS prepares and executes the SQL statement.
After the DBMS receives the SQL string buffer, it parses the statement and does a syntax check run. If the statement is not syntactically correct, the system returns an error condition to the driver, which generates a SQLException. If the statement is syntactically correct, depending on the DBMS, then many query plans usually are generated that are run through an optimizer (often a cost-based optimizer). Then, the optimum plan is translated into a binary execution plan. After the execution plan is prepared, the DBMS usually returns a handle or identifier to this optimized binary version of the SQL statement back to the application program.
The three JDBC statement (viz., Statement,
PreparedStatement, and CallableStatement)
types differ in the timing of the SQL statement preparation and
the statement execution. In the case of the simple Statement
object, the SQL is prepared and executed in one step (at least
from the application program point of view. Internally, the driver
might get the identifier, command the DBMS to execute the query,
and then discard the handle). In the case of a PreparedStatement
object, the driver stores the execution plan handle
for later use. In the case of the CallableStatement
object, the SQL statement is actually making a call
to a stored procedure that is usually already optimized.
| Note |
As you know, stored procedures are encapsulated business rules or procedures that reside in the database server. They also enforce uniformity across applications, as well as provide security to the database access. Stored procedures last beyond the execution of the program. So the application program does not spend any time waiting for the DBMS to create the execution plan. |
Now, look at each type of statement more closely and see what each has to offer a Java program.
A Statement object is created
using the createStatement()
method in the Connection
object. Table 15.7 shows all methods available for the Statement
object.
| Return Type | Method Name | |
| ResultSet | executeQuery | |
| int | executeUpdate | |
| Boolean | execute | |
| Boolean | getMoreResults | |
| void | close | |
| int | getMaxFieldSize | |
| void | setMaxFieldSize | |
| int | getMaxRows | |
| void | setMaxRows | |
| void | setEscapeProcessing | |
| int | getQueryTimeout | |
| void | setQueryTimeout | |
| void | cancel | |
| java.sql.SQLWarning | getWarnings | |
| void | clearWarnings | |
| void | setCursorName | |
| ResultSet | getResultSet | |
| int | getUpdateCount |
The most important methods are executeQuery(),
executeUpdate(), and execute().
As you create a Statement
object with a SQL statement,
the executeQuery() method
takes a SQL string. It passes the SQL string to the underlying
data source through the driver manager and gets the ResultSet
back to the application program. The executeQuery()
method returns only one ResultSet.
For those cases that return more than one ResultSet,
theexecute() method should
be used.
| Caution |
Only one ResultSet can be opened per Statement object at one time. |
For SQL statements that do
not return a ResultSet such
as the UPDATE, DELETE,
and DDL statements, the Statement
object has the executeUpdate()
method that takes a SQL string and returns an integer. This integer
indicates the number of rows that are affected by the SQL statement.
| Note |
The JDBC processing is synchronous; that is, the application program must wait for the SQL statements to complete. But because Java is a multithreaded platform, the JDBC designers suggest using threads to simulate asynchronous processing. |
The Statement object is best suited for ad hoc SQL statements or SQL statements that are executed once. The DBMS goes through the syntax run, query plan optimization, and the execution plan generation stages as soon as this SQL statement is received. The DBMS executes the query and then discards the optimized execution plan. So, if the executeQuery() method is called again, the DBMS goes through all of the steps again.
The following example program shows how to use the Statement class to access a database (The database schema is shown in Figure 15.4 earlier in this chapter). In this example, you will list all of the subjects (classes) available in our enrollment database and their location and day and times. The SQL statement for this is "SELECT ClassName, Location, DaysAndTimes FROM Classes". You will create a Statement object and pass the SQL string during the executeQuery() method call to get this data.
//Declare a method and some variables.
public void ListClasses() throws SQLException {
int i, NoOfColumns;
String ClassName,ClassLocation, ClassSchedule;
//Initialize and load the JDBC-ODBC driver.
Class.forName ("jdbc.odbc.JdbcOdbcDriver");
//Make the connection object.
Connection Ex1Con = DriverManager.getConnection( "jdbc:odbc:StudentDB;uid="admin";pw="sa");
//Create a simple Statement object.
Statement Ex1Stmt = Ex1Con.createStatement();
//Make a SQL string, pass it to the DBMS, and execute the SQL statement.
ResultSet Ex1rs = Ex1Stmt.executeQuery(
"SELECT ClassName, Location, DaysAndTimes FROM Classes");
//Process each row until there are no more rows.
// And display the results on the console.
System.out.println("Class Location Schedule");
while (Ex1rs.next()) {
// Get the column values into Java variables
ClassName = Ex1rs.getString(1);
ClassLocation = Ex1rs.getString(2);
ClassSchedule = Ex1rs.getString(3);
System.out.println(ClassName,ClassLocation,ClassSchedule);
}
}
As you can see, the program is very straightforward. You do the initial connection and so on, and create a Statement object. Pass the SQL along with the method executeQuery() call. The driver will pass the SQL string to the DBMS, which will perform the query and return the results. After the statement is done, the optimized execution plan is lost.
In the case of a PreparedStatement object, as the name implies, the application program prepares a SQL statement using the java.sql.Connection.prepareStatement() method. The prepareStatement() method takes a SQL string, which is passed to the underlying DBMS. The DBMS goes through the syntax run, query plan optimization, and the execution plan generation stages but does not execute the SQL statement. Possibly, the DBMS returns a handle to the optimized execution plan that the JDBC driver stores internally in the PreparedStatement object.
The methods of the PreparedStatement
object are shown in Table 15.8. Notice that the executeQuery(),
executeUpdate(), and execute()
methods do not take any parameters. They are just calls to the
underlying DBMS to perform the already optimized SQL statement.
| Return Type | Method Name | |
| ResultSet | executeQuery | |
| int | executeUpdate | |
| Boolean | execute |
One of the major features of a PreparedStatement
is that it can handle IN
types of parameters. The parameters are indicated in a SQL
statement by placing the ? as the parameter marker instead
of the actual values. In the Java program, the association is
made to the parameters with the setXXXX()
methods, as shown in Table 15.9. All of the setXXXX()
methods take the parameter index, which is 1 for the first "?,"
2 for the second "?,"and so on.
| Method Name | Parameter | |
| clearParameters | ( ) | |
| setAsciiStream | (int parameterIndex, java.io. InputStream x, int length) | |
| setBinaryStream | (int parameterIndex, java.io. InputStream x, int length) | |
| setBoolean | (int parameterIndex, boolean x) | |
| setByte | (int parameterIndex, byte x) | |
| setBytes | (int parameterIndex, byte x[ ]) | |
| setDate | (int parameterIndex, java.sql.Date x) | |
| setDouble | (int parameterIndex, double x) | |
| setFloat | (int parameterIndex, float x) | |
| setInt | (int parameterIndex, int x) | |
| setLong | (int parameterIndex, long x) | |
| setNull | (int parameterIndex, int sqlType) | |
| setNumeric | (int parameterIndex, Numeric x) | |
| setShort | (int parameterIndex, short x) | |
| setString | (int parameterIndex, String x) | |
| setTime | (int parameterIndex, java.sql.Time x) | |
| setTimestamp | (int parameterIndex, java.sql.Timestamp x) | |
| setUnicodeStream | (int parameterIndex, java.io.InputStream x, int length) |
| (int parameterIndex, Object x, int targetSqlType, int scale) | ||
| (int parameterIndex, Object x, int targetSqlType) | ||
| (int parameterIndex, Object x) |
In the case of the PreparedStatement, the driver actually sends only the execution plan ID and the parameters to the DBMS. This results in less network traffic and is well-suited for Java applications on the Internet. The PreparedStatement should be used when you need to execute the SQL statement many times in a Java application. But remember, even though the optimized execution plan is available during the execution of a Java program, the DBMS discards the execution plan at the end of the program. So, the DBMS must go through all of the steps of creating an execution plan every time the program runs. The PreparedStatement object achieves faster SQL execution performance than the simple Statement object, as the DBMS does not have to run through the steps of creating the execution plan.
The following example program shows how to use the PreparedStatement class to access a database. (The database schema is shown in Figure 15.4 earlier in this chapter.) In this example, you will be a little more aggressive and optimize the example you developed in the Statement example. The simple Statement example can be improved in a couple of major ways. First, the DBMS will go through building the execution plan every time. So you will make it a PreparedStatement. Secondly, the query will list all courses which could scroll away. You will improve this situation by building a parameterized query as follows:
//Declare class variables
Connection Con;
PreparedStatement PrepStmt;
boolean Initialized = false;
private void InitConnection() throws SQLException {
//Initialize and load the JDBC-ODBC driver.
Class.forName ("jdbc.odbc.JdbcOdbcDriver");
//Make the connection object.
Con = DriverManager.getConnection( "jdbc:odbc:StudentDB;uid="admin";pw="sa");
//Create a prepared Statement object.
PrepStmt = Ex1Con.prepareStatement(
"SELECT ClassName, Location, DaysAndTimes FROM Classes WHERE ClassName = ?");
Initialized = True;
}
public void ListOneClass(String ListClassName) throws SQLException {
int i, NoOfColumns;
String ClassName,ClassLocation, ClassSchedule;
if (! Initialized) {
InitConnection();
}
// Set the SQL parameter to the one passed into this method
PrepStmt.setString(1,ListClassName);
ResultSet Ex1rs = PrepStmt.executeQuery()
//Process each row until there are no more rows and
// display the results on the console.
System.out.println("Class Location Schedule");
while (Ex1rs.next()) {
// Get the column values into Java variables
ClassName = Ex1rs.getString(1);
ClassLocation = Ex1rs.getString(2);
ClassSchedule = Ex1rs.getString(3);
System.out.println(ClassName,ClassLocation,ClassSchedule);
}
}
Now, if a student wants to check the details of one subject interactively, the above example program can be used. You will save execution time and network traffic from the second invocation onwards because you are using the PreparedStatement object.
For a secure, consistent, and manageable multi-tier client/server system, the data access should allow the use of stored procedures. Stored procedures centralize the business logic in terms of manageability and also in terms of running the query. Java applets running on clients with limited resources cannot be expected to run huge queries. But the results are important to those clients. JDBC allows the use of stored procedures by the CallableStatement class and with the escape clause string.
A CallableStatement object is created by the prepareCall() method in the Connection object. The prepareCall() method takes a string as the parameter. This string, called an escape clause, is of the form
{[? =] call <stored procedure name> [<parameter>,<parameter> ...]}
The CallableStatement class supports parameters. These parameters are of the OUT kind from a stored procedure or the IN kind to pass values into a stored procedure. The parameter marker (question mark) must be used for the return value (if any) and any output arguments, because the parameter marker is bound to a program variable in the stored procedure. Input arguments can be either literals or parameters. For a dynamic parameterized statement, the escape clause string takes the form:
{[? =] call <stored procedure name> [<?>,<?> ...]}
The OUT parameters should
be registered using the registerOutparameter()
method-as shown in Table 15.10- before the call to the executeQuery(),
executeUpdate(), or execute()
methods.
| Parameter | ||
| (int parameterIndex, int sqlType) | ||
| (int parameterIndex, int sqlType, int scale) |
After the stored procedure is executed, the DBMS returns the result
value to the JDBC driver. This return value is accessed by the
Java program using the methods in Table 15.11.
| Return Type | Method Name | |
| Boolean | getBoolean | |
| byte | getByte | |
| byte[] | getBytes | |
| java.sql.Date | getDate | |
| double | getDouble | |
| float | getFloat | |
| int | getInt | |
| long | getLong | |
| Numeric | getNumeric | |
| Object | getObject | |
| short | getShort | |
| String | getString | |
| java.sql.Time | getTime | |
| java.sql.Timestamp | getTimestamp |
Miscellaneous
| boolean | wasNull |
If a student wants to find out the grades for a subject in the database schema shown in Figure 15.4, you need to do many operations on various tables such as find all assignments for the student, match them with class name, calculate grade points, and so on. This is a business logic (academics is also a business and the concepts apply here, too !) well-suited for a stored procedure. In this example, we give the stored procedure a student ID, class ID, and it will return the grade! Your client program becomes simple, and all the processing is done at the server. This is where you will use a CallableStatement.
The stored procedure call is of the following form:
studentGrade = getStudentGrade(StudentID,ClassID).
In the JDBC call, you will create a CallableStatement object with the ? symbol as placeholders for parameters and then connect Java variables to the parameters as shown in the following example:
public void DisplayGrade(String StudentID, String ClassID) throws SQLException {
Âint Grade;
//Initialize and load the JDBC-ODBC driver.
Class.forName ("jdbc.odbc.JdbcOdbcDriver");
//Make the connection object.
Connection Con = DriverManager.getConnection( "jdbc:odbc:StudentDB;uid="admin";pw="sa");
//Create a Callable Statement object.
CallableStatement CStmt = Con.prepareCall({?=call getStudentGrade[?,?]});
// Now tie the placeholders with actual parameters.
// Register the return value from the stored procedure
// as an integer type so that the driver knows how to handle it.
// Note the type is defined in the java.sql.Types.
CStmt.registerOutParameter(1,java.sql.Types.INTEGER);
// Set the In parameters (which are inherited from the PreparedStatement class)
CStmt.setString(1,StudentID);
CStmt.setString(2,ClassID);
// Now we are ready to call the stored procedure
int RetVal = CStmt.executeUpdate();
// Get the OUT parameter from the registered parameter
// Note that we get the result from the CallableStatement object
Grade = CStmt.getInt(1);
// And display the results on the console.
System.out.println(" The Grade is: ");
System.out.println(Grade);
}
As you can see, JDBC has minimized the complexities of getting results from a stored procedure. It still is a little involved, but is simpler. Maybe in the future, these steps will become simpler.
Now that you have seen how to communicate with the underlying DBMS with SQL, see what you need to do to process the results sent back from the database as a result of the SQL statements.
The ResultSet object is actually
a tubular data set; that is, it consists of rows of data organized
in uniform columns. In JDBC, the Java program can see only one
row of data at one time. The program uses the next()
method to go to the next row. JDBC does not provide any methods
to move backwards along the ResultSet
or to remember the row positions (called bookmarks in ODBC).
Once the program has a row, it can use the positional index (1
for the first column, 2 for the second column, and so on) or the
column name to get the field value by using the getXXXX()
methods. Table 15.12 shows the methods associated with the ResultSet
object.
| Return Type | Method Name | |
| boolean | next | |
| void | close | |
| boolean | wasNull | |
| Get Data by Column Position | ||
| java.io.InputStream | getAsciiStream | |
| java.io.InputStream | getBinaryStream | |
| boolean | getBoolean | |
| byte | getByte | |
| byte[] | getBytes | |
| java.sql.Date | getDate | |
| double | getDouble | |
| float | getFloat | |
| int | getInt | |
| long | getLong | |
| java.sql.Numeric | getNumeric | |
| Object | getObject | |
| short | getShort | |
| String | getString | |
| java.sql.Time | getTime | |
| java.sql.Timestamp | getTimestamp | |
| java.io.InputStream | getUnicodeStream | |
| Get Data by Column Name | ||
| java.io.InputStream | getAsciiStream | |
| java.io.InputStream | getBinaryStream | |
| boolean | getBoolean | |
| byte | getByte | |
| byte[] | getBytes | |
| java.sql.Date | getDate | |
| double | getDouble | |
| float | getFloat | |
| int | getInt | |
| long | getLong | |
| java.sql.Numeric | getNumeric | |
| Object | getObject | |
| short | getShort | |
| String | getString | |
| java.sql.Time | getTime | |
| java.sql.Timestamp | getTimestamp | |
| java.io.InputStream | getUnicodeStream | |
| int | findColumn | |
| SQLWarning | getWarnings | |
| void | clearWarnings | |
| String | getCursorName | |
| ResultSetMetaData | getMetaData | |
As you can see, the ResultSet methods-even though there are many-are very simple. The major ones are the getXXX() methods. The getMetaData() method returns the meta data information about a ResultSet. The DatabaseMetaData also returns the results in the ResultSet form. The ResultSet also has methods for the silent SQLWarnings. It is a good practice to check any warnings using the getWarning() method that returns a null if there are no warnings.
The SQLException class in
JDBC provides a variety of information regarding errors that occurred
during a database access. The SQLException
objects are chained so that a program can read them in order.
This is a good mechanism, as an error condition can generate multiple
errors and the final error might not have anything to do with
the actual error condition. By chaining the errors, you can actually
pinpoint the first error. Each SQLException
has an error message and vendor-specific error code. Also associated
with a SQLException is a
SQLState string that follows
the XOPEN SQLstate
values defined in the SQL specification. Table 15.13 lists the
methods for the SQLException
class.
| Return Type | Method Name | Parameter |
| SQLException | SQLException | (String reason, String SQLState, int vendorCode) |
| SQLException | SQLException | (String reason, String SQLState) |
| SQLException | SQLException | (String reason) |
| SQLException | SQLException | |
| String | getSQLState | |
| int | getErrorCode | |
| SQLException | getNextException | |
| void | setNextException | (SQLException ex) |
Unlike the SQLExceptions
that the program knows have happened because of raised exceptions,
the SQLWarnings do not cause
any commotion in a Java program. The SQLWarnings
are tagged to the object whose method caused the Warning.
So you should check for Warnings
using the getWarnings() method
that is available for all objects. Table 15.14 lists the methods
associated with the SQLWarnings
class.
| Return Type | Function Name | Parameter |
| SQLWarning | SQLWarning | (String reason, String SQLstate, int vendorCode) |
| SQLWarning | SQLWarning | (String reason, String SQLstate) |
| SQLWarning | SQLWarning | (String reason) |
| SQLWarning | SQLWarning | |
| SQLWarning | getNextWarning | |
| void | setNextWarning | (SQLWarning w) |
Now that you have seen all of the main database-related classes, look at some of the supporting classes that are available in JDBC. These classes include Date, Time, TimeStamp, Numeric, and so on. Most of these classes extend the basic Java classes to add the capability to handle and translate data types that are specific to SQL.
This package gives a Java program the capability to handle SQL
DATE information with only year, month, and day values. This package
contrasts with the java.util.Date,
where the time in hours, minutes, and seconds is also kept (see
Table 15.15).
| Return Type | Method Name | Parameter |
| Date | Date | (int year, int month, int day) |
| Date | valueOf | (String s) |
| String | toString |
As seen in Table 15.16, the java.sql.Time
adds the Time object to the
java.util.Date package to
handle only hours, minutes, and seconds. java.sql.Time
is also used to represent SQL TIME
information.
| Return Type | Method Name | Parameter |
| Time | Time | (int hour, int minute, int second) |
| Time | Time | valueOf(String s) |
| String | toString |
The java.sql.Timestamp package
adds the Timestamp class
to the java.util.Date package.
It adds the capability of handling nanoseconds. But the granularity
of the subsecond timestamp depends on the database field as well
as the operating system (see Table 15.17).
| Return Type | Method Name | Parameter |
| Timestamp | Timestamp | (int year, int month, int date, inthour, int minute, int second, int nano); |
| Timestamp | valueOf | (String s) |
| String | toString | |
| int | getNanos | |
| void | setNanos | (int n) |
| boolean | equals | (Timestamp ts) |
In JDBC, the SQL types are defined in the java.sql.Types class and the different numeric types are handled in the java.sql.Numeric class.
This class defines a set of XOPEN
equivalent integer constants that identify SQL types. The constants
are final types. Therefore, they cannot be redefined in applications
or applets. Table 15.18 lists the constant names and their values.
| Constant Name | |
| BIGINT | |
| BINARY | |
| BIT | |
| CHAR | |
| DATE | |
| DECIMAL | |
| DOUBLE | |
| FLOAT | |
| INTEGER | |
| LONGVARBINARY | |
| LONGVARCHAR | |
| NULL | |
| NUMERIC | |
| OTHER | |
| REAL | |
| SMALLINT | |
| TIME | |
| TIMESTAMP | |
| TINYINT | |
| VARBINARY | |
| VARCHAR |
In this chapter, you saw how JDBC has ushered in an era of simple yet powerful database access for Java programs. JDBC is an important step in the right direction to elevate the Java language to the Java platform. The Java APIs-including the Enterprise APIs (JDBC, RMI, Serialization, and IDL), Security APIs, and the Server APIs-are the essential ingredients for developing enterprise-level, distributed, multi-tier client/server applications.
The JDBC specification life cycle happened in the speed of the Net-one Net year is widely clocked as equaling seven normal years. The version 1.01 JDBC specification is fixed, so the developers and driver vendors are not chasing a moving target.
Another factor in favor of JDBC is its similarity to ODBC. JavaSoft made the right decision to follow ODBC philosophy and abstractions, thus making it easy for ISVs and users to leverage their ODBC experience and existing ODBC drivers. In the JDBC specification, this goal is described as "JDBC must be implementable on top of common database interfaces."
By making JDBC a part of the Java language, you received all of the advantages of the Java language concepts for database access. Also, as all implementers have to support the Java APIs, JDBC has become a universal standard. This philosophy, stated in the JDBC specification as "provide a Java interface that is consistent with the rest of the Java system," makes JDBC an ideal candidate for use in Java-based database development.
Another good design philosophy is the driver independence of the
JDBC. The underlying database drivers can either be native libraries-such
as a dynamic link lbrary (.dll) for the Windows system or Java
routines connecting to listeners. The full Java implementation
of JDBC is suitable for a variety of Network and other Java OS
computers, thus making JDBC a versatile set of APIs.
| Note |
In my humble opinion, the most important advantage of JDBC is its simplicit and versatility. The goal of the designers was to keep the API and common cases simple and "support the weird stuff in separate interfaces." Also, they wanted to use multiple methods for multiple functionality. They have achieved their goals even in this first version. For example, the statement object has the executeQuery() method for SQL statements returning rows of data, and it has the executeUpdate() method for statements without data to return. Also, uncommon cases, such as statements returning multiple ResultSets, have a separate method-execute(). |
As more applications are developed with JDBC and as the Java platform matures, more and more features will be added to JDBC. One of the required features, especially for client/server processing, is a more versatile cursor. The current design leaves the cursor management details to the driver. I would prefer more application-level control for scrollable cursors, positioned update/delete capability, and so on. Another related feature is the bookmark feature, which is useful especially in a distributed processing environment such as the Internet.