{kind=link}
{kind=link}
{kind=link}




by Mark Wutka
The Web server is the home of a Java applet. Not only does the applet live there, it must rely on the Web server for any information or files it wants to download. As some of the applet security restrictions are lifted and replaced with a better security mechanism, this will not be the case. For now, however, the Web server is the only place an applet can count on being able to access. Applications, on the other hand, may access data in countless ways, but still find Web servers to be a wonderful source of information.
The URL class allows you to access any URL on the World Wide Web, as long as your browser or Java environment supports the protocol for the URL. You can safely assume that your environment supports the HTTP protocol. Other protocols such as FTP may not be available, however. Keep in mind that if you open an URL and read it yourself, there is no way to take the data you read and display it as a fully-formatted HTML page unless you do it yourself. If you want to open an URL and have your browser display it, you should use the showDocument method in the Applet class, which is discussed in the section, "Loading Another URL from an Applet," in Chapter 7 "Creating Smarter Forms."
The URL class is really just a class for naming resources on the World Wide Web, much like the File class represents file names, but not the contents of a file. In order to get the contents of an URL, you need to open an input stream to the URL. You can do this one of two ways. The simplest way is to call the openStream method in the URL class:
URL someURL = new URL("http://abcdef.com/mydocument.html");
InputStream inStream = someURL.openStream();
This input stream will provide you with the contents of the file named by the URL. This method is most useful when you are only concerned with the file contents and not with any of the HTTP headers associated with the file. To get these, you need to use the URLConnection class.
The URLConnection class represents a network connection to a WWW resource. When you open an input stream on an URL, it really opens an URLConnection and then calls the getInputStream in the URLConnection object. The following code fragment is the equivalent of the previous example:
URL someURL = new URL("http://abcdef.com/mydocument.html");
URLConnection urlConn = someURL.openConnection();
InputStream inStream = urlConn.getInputStream();
The advantage of the URLConnection class is that it gives you much finer control over an URL connection. For example, you can retrieve the headers associated with the file. The two header fields that you will probably be most interested in are the content type and content length. You can fetch these with the getHeaderField and getHeaderFieldInt methods:
String contentType = urlConn.getHeaderField("content-type");
int contentLength = urlConn.getHeaderFieldInt(
"content-length", -1); // returns -1 if length isn't specified
These header fields are so popular, in fact, that they have their own special methods that do the equivalent of the above code-getContentType and getContentLength:
String contentType = urlConn.getContentType(); int contentLength = urlConn.getContentLength();
Listing 6.1 shows a sample applet that uses an URL class to read its own .class file.
Listing 6.1 Source Code for FetchURL.java
import java.applet.*;
import java.awt.*;
import java.net.*;
import java.io.*;
// This applet demonstrates the use of the URL and URLConnection
// class to read a file from a Web server. The applet reads its
// own .class file, because you can always be sure it exists.
public class FetchURL extends Applet
{
byte[] appletCode; // Where to store the contents of the .class file
public void init()
{
try {
// Open a URL to this applet's .class file. You can locate it by
// using the getCodeBase method and the applet's class name.
URL url = new URL(getCodeBase(),
getClass().getName()+".class");
// Open a URLConnection to the URL
URLConnection urlConn = url.openConnection();
// See if you can find out the length of the file. This allows you to
// create a buffer exactly as large as you need.
int length = urlConn.getContentLength();
// Because you can't be sure of the size of the .class file, use a
// ByteArrayOutputStream as a temporary container. Once you are finished
// reading, you can convert it to a byte array.
ByteArrayOutputStream tempBuffer;
// If you don't know the length of the .class file, use the default size
if (length < 0) {
tempBuffer = new ByteArrayOutputStream();
} else {
tempBuffer = new ByteArrayOutputStream(length);
}
// Get an input stream to this URL
InputStream instream = urlConn.getInputStream();
// Read the contents of the URL and copy it to the temporary buffer
int ch;
while ((ch = instream.read()) >= 0) {
tempBuffer.write(ch);
}
// Convert the temp buffer to a byte array (you don't do anything with
// the array in this applet other than take its size).
appletCode = tempBuffer.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
}
public void paint(Graphics g)
{
g.setColor(Color.black);
if (appletCode == null) {
g.drawString("I was unable to read my .class file",
10, 30);
} else {
g.drawString("This applet's .class file is "+
appletCode.length+" bytes long.", 10, 30);
}
}
}
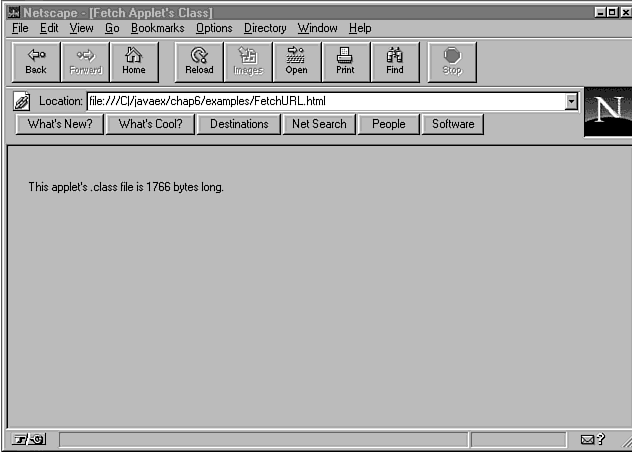
Figure 6.1 shows the output from the FetchURL applet.
Figure 6.1 : An applet can perform an HTTP GET using the URL class.
The FetchURL applet is a typical example of an applet that opens an URL and reads data from it. For example purposes, the applet reads its own .class file. There is no advantage to reading a .class file, but for example purposes it is quite handy, because you know for sure that the .class file must be there. If the .class file wasn't there, the applet wouldn't run in the first place.
The applet first opens the URL, and then gets an input stream
for the URL. It tries to get the content length, which indicates
how much data there is to retrieve. This value isn't always available,
however, so the applet uses ByteArrayOutputStream
as a temporary storage mechanism.
| Tip |
Vectors and byte array output streams are extremely handy storage containers when you don't know the size of the data you are storing. You should use a vector whenever you need to store an unknown number of objects. The byte array output stream is a handy alternative to the vector when you are storing bytes. |
Once the applet has read its .class file, it simply displays a message telling how many bytes it read.
If, for some reason, you decide that you want to bypass the URL and URLConnection classes and speak HTTP directly over a socket, you are probably a glutton for punishment or just a genuine bit-head. Actually, the HTTP protocol is very simple, so it isn't that big a deal to open up a socket and fetch information. All you need to do is open the socket, send a GET message, and start reading.
When you read data from an HTTP server directly over a socket, you'll get all the header information first. Each line in the header is terminated by a carriage return and then a line feed (in Java, "\r\n"). The end of the header section is marked by a blank line. After that comes the data, in whatever form the server sends it. The "content-type" header tells you what type of data to expect. If you're just reading a text file, it should be "text/plain."
Listing 6.2 shows an applet that uses a socket connection to fetch a file from a Web server. Like the example in Listing 6.1, this applet fetches its own .class file.
import java.applet.*; import java.awt.*;
Listing 6.2 Source Code for FetchSockURL.java
import java.net.*;
import java.io.*;
// This applet shows you how to open up a socket to an HTTP server
// and read a file. The applet reads its own .class file, because
// you can always be sure it exists.
public class FetchSockURL extends Applet
{
byte[] appletCode; // Where to store the contents of the .class file
public void init()
{
try {
// If the port number returned for the code base is -1, use the
// default http port of 80.
int port = getCodeBase().getPort();
if (port < 0) port = 80;
// Open up a socket to the Web server where this applet came from
Socket sock = new Socket(getCodeBase().getHost(),port);
// Get input and output streams for the socket connection
DataInputStream inStream = new DataInputStream(
sock.getInputStream());
DataOutputStream outStream = new DataOutputStream(
sock.getOutputStream());
// Send the GET request to the server
// The request is of the form: GET filename HTTP/1.0
// In this case, the filename will be the applet's filename as returned
// by the getCodeBase method. Notice that you send two \r\n's
// The first one terminates the request line, the second indicates the
// end of the request header.
outStream.writeBytes("GET "+
getCodeBase().getFile()+getClass().getName()+
".class HTTP/1.0\r\n\r\n");
// Just to show you how it's done, look through the headers for
// the content length. First, assume it's -1.
int length = -1;
String currLine;
// Read the next line from the header, quit if you hit EOF
while ((currLine = inStream.readLine()) != null)
{
// if the length of the line is 0, you just hit the end of the header
if (currLine.length() == 0) break;
// See if it's the content-length header
if (currLine.toLowerCase().startsWith(
"content-length:")) {
// "content-length:" is 15 characters long, so parse the length starting at
// offset 15 (the 16th character). Catch any exceptions when parsing
// this number - it's not so important that you have to quit.
try {
length = Integer.valueOf(
currLine.substring(15)).
intValue();
} catch (Exception ignoreMe) {
}
}
}
// Because you can't be sure of the size of the .class file, use a
// ByteArrayOutputStream as a temporary container. Once you are finished
// reading, you can convert it to a byte array.
ByteArrayOutputStream tempBuffer;
// If you don't know the length of the .class file, use the default size
if (length < 0) {
tempBuffer = new ByteArrayOutputStream();
} else {
tempBuffer = new ByteArrayOutputStream(length);
}
// Read the contents of the URL and copy it to the temporary buffer
int ch;
while ((ch = inStream.read()) >= 0) {
tempBuffer.write(ch);
}
// Convert the temp buffer to a byte array (you don't do anything with
// the array in this applet other than take its size.
appletCode = tempBuffer.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
}
public void paint(Graphics g)
{
g.setColor(Color.black);
if (appletCode == null) {
g.drawString("I was unable to read my .class file",
10, 30);
} else {
g.drawString("This applet's .class file is "+
appletCode.length+" bytes long.", 10, 30);
}
}
}
Like the FetchURL applet, the FetchSockURL applet reads its own .class file from the Web server. FetchSockURL doesn't use the built-in URL class, however. Instead, it creates a socket connection to the Web server. Once this connection is made, the applet sends a GET request to the Web server to retrieve the .class file. The GET request usually looks something like this:
GET /classes/FetchSockURL.class HTTP/1.0
This line is followed by a blank line, indicating the end of the HTTP headers. You can send your own headers immediately after the GET request if you like. Just make sure they appear before the blank line. The FetchSockURL applet actually writes out the blank line in the same statement where it writes out the GET request, so you'll need to remove the \r\n from the end of the writeBytes statement if you add your own headers. If you do that, don't forget to write out a blank line after your headers.
Once the GET request has been sent to the server, the applet begins reading lines from the socket connection. The server will send a number of header lines, terminated by a blank line. This will be followed by the actual content of the page.
The FetchSockURL applet scans through the headers looking for the content length header field, which usually looks like this:
Content-length: 1234
Like the FetchURL applet, the FetchSockURL applet can handle situations where the content length is unknown. It uses the same technique of writing the data to a byte array output stream as it reads it. You can tell when you have reached the end of the content because you'll hit the end of file on the socket (the read method will return -1).
Many Web servers allow you to get information based on a query. In other words, you don't just ask for a file, you ask for a file and pass some query parameters. This determines the information you get back. This is most often used in Web search engines. Most Web servers support an interface called CGI-Common Gateway Interface. While you don't really need to know the intricacies of CGI to write queries, you do need to know how it expects queries to look.
A CGI query looks like a regular URL except it has extra parameters on the end. The query portion starts with a "?" and is followed by a list of parameters. Each parameter in the query is separated by a "&", and parameter values are specified in a "name=value" format. Parameters are not required to have values. A CGI query to run a script called find-people, taking parameters called name, age, and occupation, would look like this:
http://localhost/cgi-bin/find-people?occupation=engineer&age=30&name=smith
Knowing this, you can easily write a class that takes an URL and a set of parameters and generates a query URL. Listing 6.3 shows just such a class.
Listing 6.3 Source Code for URLQuery.java
import java.net.*;
import java.util.*;
// This class provides a way to create an URL to perform a query
// against a Web server. The query takes the base URL of the
// the program you are sending the query to, and a set of properties
// that will be converted into a query string.
public class URLQuery extends Object
{
public static URL createQuery(URL originalURL, Properties parameters)
throws MalformedURLException
{
// Queries have the file name followed by a ?
String newFile = originalURL.getFile()+"?";
// Now append the query parameters to the filename
Enumeration e = parameters.propertyNames();
boolean firstParameter = true;
while (e.hasMoreElements()) {
String propName = (String) e.nextElement();
// Parameters are separated by &'s, if this isn't the first parameter
// append a & to the current query string (file name)
if (!firstParameter) newFile += "&";
// Add the variable name to the query string
newFile += URLEncoder.encode(propName);
// Get the variable's value
String prop = parameters.getProperty(propName);
// If the variable isn't null, append "=" followed by the value
if (prop != null) {
newFile += "="+URLEncoder.encode(prop);
}
firstParameter = false;
}
// Return the full URL consisting of the original protocol, host, and port
// and the new, enhanced filename, which contains all the query parameters.
// This URL is suitable for opening with showDocument or any other URL
// operation.
return new URL(originalURL.getProtocol(),
originalURL.getHost(), originalURL.getPort(), newFile);
}
}
You retrieve the results of a query just like you retrieve any other file on the Web. You can open up a stream directly from the URL, you can get a URLConnection object, or you can open up a socket and speak directly to the server. Because queries frequently return Web pages, you may want to use the openDocument method in the Applet class. This enables you to see the results of the query all neatly formatted by the Web browser instead of the raw HTML codes that you get from an input stream. Listing 6.4 shows an applet that submits a query to the Lycos search engine (http://www.lycos.com) and displays the results using showDocument.
Listing 6.4 Source Code for LycosQuery.java
import java.applet.*;
import java.util.*;
import java.net.*;
import java.io.*;
// This applet performs a query against the Lycos search engine
// and opens up the results as a new document.
public class LycosQuery extends Applet
{
public void init()
{
try {
// Create the base URL to the lycos query
URL url = new URL(
"https://www.lycos.com/cgi-bin/pursuit");
Properties queryProps = new Properties();
// Fill in the query variables. These were determined by looking
// at the Lycos query form. You search on the terms "java" and "cgi"
// requesting a maximum of 20 entries. The minscore value of .5 is
// what Lycos calls a "good match".
queryProps.put("query", "java cgi");
queryProps.put("matchmode", "and");
queryProps.put("maxhits", "20");
queryProps.put("minscore", ".5");
queryProps.put("terse", "standard");
// Create the query URL
URL fullURL = URLQuery.createQuery(url, queryProps);
// Open up the results as a new document
getAppletContext().showDocument(fullURL);
} catch (Exception e) {
e.printStackTrace();
}
}
}
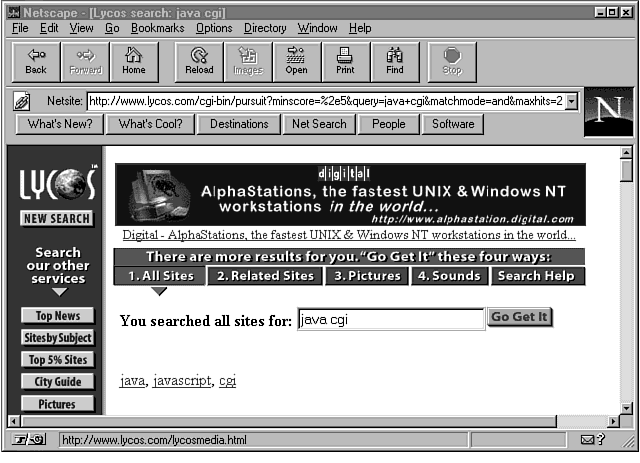
Figure 6.2 shows the results of the Lycos query generated by the LycosQuery applet.
Figure 6.2 : You can create a query and then use showDocument to display the results.
Web queries are actually something of a hack. They use the HTTP GET message, which was originally intended to retrieve files. A query actually sends data to the Web server embedded in the name of the file it is requesting. One of the problems you can encounter with Web queries is that they are limited in size. You can't use a query to send back a large block of text like an e-mail message or a problem report. The HTTP POST message can handle large blocks of data. In fact, that's what it was intended for. Most query programs, at least the well-written ones, can handle requests either as a GET or a POST message.
A GET method sends only an HTTP header in its message. A POST, on the other hand, has both a header and content. In this way, the POST message is very similar in structure to an HTTP response. You are required by the HTTP protocol to include a Content-length: field in a POST message.
You have to do a number of extra things when sending a POST message with the URLConnection class. First, you must enable output on the connection by calling setDoOutput:
myURLConnection.setDoOutput(true);
For good measure, you should also call setDoInput:
myURLConnection.setDoInput(true);
Next, you should disable caching. You want to make sure that your information goes all the way to the server, and that the response you receive is really from the server and not from the cache:
myURLConnection.setUseCaches(false);
You should set a content type for the data you are sending. A typical content type would be application/octet-stream:
myURLConnection.setRequestProperty("Content-type",
"application/octet-stream");
You are required to send a content length in a POST message. You can set this the same way you set the content type:
myURLConnection.setRequestProperty("Content-length",
""+stringToSend.length()); // cheap way to convert int to string
Once you have the headers taken care of, you can open up an output stream and write the content to the stream:
DataOutputStream outStream = new DataOutputStream(
myURLConnection.getOutputStream());
outStream.writeBytes(stringToSend());
Make sure that the string you send is terminated with \r\n.
Once you have sent the information for the post, you can open up an input stream and read the response back from the server just as you did with a GET. Listing 6.5 shows an application that sends a POST message to one of the NCSA's example CGI programs.
Listing 6.5 Source Code for URLPost.java
import java.net.*;
import java.io.*;
public class URLPost extends Object
{
public static void main(String args[])
{
try {
URL destURL = new URL(
"http://hoohoo.ncsa.uiuc.edu/cgi-bin/test-cgi/foo");
// The following request data mimics what the NCSA example CGI
// form for this CGI program would send.
String request = "button=on\r\n";
URLConnection urlConn = destURL.openConnection();
urlConn.setDoOutput(true); // we need to write
urlConn.setDoInput(true); // just to be safe...
urlConn.setUseCaches(false); // get info fresh from server
// Tell the server what kind of data you are sending - in this case,
// just a stream of bytes.
urlConn.setRequestProperty("Content-type",
"application/octet-stream");
// Must tell the server the size of the data you are sending. This also
// tells the URLConnection class that you are doing a POST instead
// of a GET.
urlConn.setRequestProperty("Content-length", ""+request.length());
// Open an output stream so you can send the info you are posting
DataOutputStream outStream = new DataOutputStream(
urlConn.getOutputStream());
// Write out the actual request data
outStream.writeBytes(request);
outStream.close();
// Now that you have sent the data, open up an input stream and get
// the response back from the server
DataInputStream inStream = new DataInputStream(
urlConn.getInputStream());
int ch;
// Dump the contents of the request to System.out
while ((ch = inStream.read()) >= 0) {
System.out.print((char) ch);
}
inStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
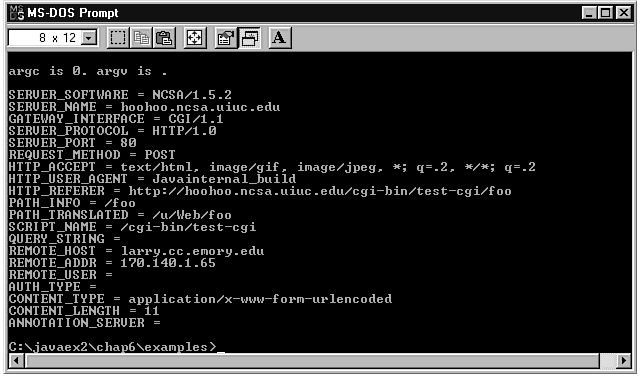
Figure 6.3 shows the working of this application.
Figure 6.3 : A Java applet or application can use the URL class to perform an HTTP POST.
You have already seen the basic differences between the GET
and the POST messages.
If you want to perform a POST
with a raw socket connection, rather than using the URLConnection
class, you don't have to do a whole lot. It is basically the same
method you used when you wrote a socket-based HTTP GET,
but in addition to sending the GET
command, you must also send the "Content-type," and
"Content-length" messages, as well as the request data.
Listing 6.6 shows the socket-based equivalent of the example program in Listing 6.5.
Listing 6.6 Source Code for PostSockURL.java
import java.net.*;
import java.io.*;
// This applet shows you how to open up a socket to an HTTP server
// and post data to a server. It posts information to one of the
// example CGI programs set up by the NCSA.
public class PostSockURL extends Object
{
public static void main(String args[])
{
try {
// Open up a socket to the Web server where this applet came from
Socket sock = new Socket("hoohoo.ncsa.uiuc.edu", 80);
// Get input and output streams for the socket connection
DataInputStream inStream = new DataInputStream(
sock.getInputStream());
DataOutputStream outStream = new DataOutputStream(
sock.getOutputStream());
// This request is what is sent by the NCSA's example form
String request = "button=on\r\n";
// Send the POST request to the server
// The request is of the form: POST filename HTTP/1.0
outStream.writeBytes("POST /cgi-bin/test-cgi/foo "+
" HTTP/1.0\r\n");
// Next, send the content type (don't forget the \r\n)
outStream.writeBytes(
"Content-type: application/octet-stream\r\n");
// Send the length of the request
outStream.writeBytes(
"Content-length: "+request.length()+"\r\n");
// Send a \r\n to indicate the end of the header
outStream.writeBytes("\r\n");
// Now send the information you are posting
outStream.writeBytes(request);
// Dump the response to System.out
int ch;
while ((ch = inStream.read()) >= 0) {
System.out.print((char) ch);
}
// We're done with the streams, so close them
inStream.close();
outStream.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
One of the early problems that plagued Web page designers was how to give information to the client browser for it to remember. If you had one million people accessing your Web server, you don't want to keep information for each one of them on your server if their browsers could just as easily store the information. Fortunately, Netscape noticed this problem fairly early and came up with the notion of a cookie.
A cookie is really just a piece of information that has a name, a value, a domain, and a path. Whenever you open up an URL to the cookie's domain and access any files along the cookie's path, the cookie's name and value are passed to the server when you open the URL. A typical use of this might be an access count or a user name. Netscape defined a request header tag called "Cookie:" that is used to pass cookie name-value pairs to the server. A server can set cookie values in a browser by sending a Set-cookie tag in the response header.
You should now be able to create Java applications that can open up URLs directly, without the interference of a browser, so you may want to support the cookie protocol. It would be nice if this protocol could be built right into the URL and URLConnection classes. You are welcome to tackle this problem. At first, it would seem like a simple thing to do, but you will find that the URLConnection class, although it has methods to set the desired fields in a request header, will not actually pass these fields to the server. This means that you can call setRequestProperty("Cookie", "Something=somevalue") all day long and the server will never see it. If you want to speak cookies, you'll have to speak HTTP over a socket. Luckily for you, this chapter contains code to do just that.
Listing 6.7 shows a Cookie class that represents the information
associated with a cookie. It doesn't actually send or receive
cookies; it is more like a Cookie data type. One interesting feature
is that its constructor can create a cookie from the string returned
by the cookie's toString method, making it easy to store cookies
in a file and retrieve them.
| Tip |
It is often useful to create a string representation of an object that can be used to re-create the object at a later time. While you can use object serialization to read and write objects to a file, a string representation can be edited with a simple text editor. |
Listing 6.7 Source Code for Cookie.java
import java.net.*;
import java.util.*;
// This class represents a Netscape cookie. It can parse its
// values from the string from a Set-cookie: response (without
// the Set-cookie: portion, of course). It is little more than
// a fancy data structure.
public class Cookie
{
// Define the standard cookie fields
public String name;
public String value;
public Date expires;
public String domain;
public String path;
public boolean isSecure;
// cookieString is the original string from the Set-cookie header.
// Just save it rather than trying to regenerate for the toString
// method. Note that since this class can initialize itself from this
// string, it can be used to save a persistent copy of this class!
public String cookieString;
// Initialize the cookie based on the origin URL and the cookie string
public Cookie(URL sourceURL, String cookieValue)
{
domain = sourceURL.getHost();
path = sourceURL.getFile();
parseCookieValue(cookieValue);
}
// Initialize the cookie based solely on its cookie string
public Cookie(String cookieValue)
{
parseCookieValue(cookieValue);
}
// Parse a cookie string and initialize the values
protected void parseCookieValue(String cookieValue)
{
cookieString = cookieValue;
// Separate out the various fields, which are separated by ;'s
StringTokenizer tokenizer = new StringTokenizer(
cookieValue, ";");
while (tokenizer.hasMoreTokens()) {
// Eliminate leading and trailing white space
String token = tokenizer.nextToken().trim();
// See if the field is of the form name=value or if it is just
// a name by itself.
int eqIndex = token.indexOf('=');
String key, value;
// If it is just a name by itself, set the field's value to null
if (eqIndex == -1) {
key = token;
value = null;
// Otherwise, the name is to the left of the '=', value is to the right
} else {
key = token.substring(0, eqIndex);
value = token.substring(eqIndex+1);
}
isSecure = false;
// convert the key to lowercase for comparison with the standard field names
String lcKey = key.toLowerCase();
if (lcKey.equals("expires")) {
expires = new Date(value);
} else if (lcKey.equals("domain")) {
if (isValidDomain(value)) {
domain = value;
}
} else if (lcKey.equals("path")) {
path = value;
} else if (lcKey.equals("secure")) {
isSecure = true;
// If the key wasn't a standard field name, it must be the cookie's name
// You don't use the lowercase version of the name here.
} else {
name = key;
this.value = value;
}
}
}
// isValidDomain performs the standard cookie domain check. A cookie
// domain must have at least two portions if it ends in
// .com, .edu, .net, .org, .gov, .mil, or .int. If it ends in something
// else, it must have 3 portions. In other words, you can't specify
// .com as a domain, it has to be something.com, and you can't specify
// .ga.us as a domain, it has to be something.ga.us.
protected boolean isValidDomain(String domain)
{
// Eliminate the leading period for this check
if (domain.charAt(0) == '.') domain = domain.substring(1);
StringTokenizer tokenizer = new StringTokenizer(domain, ".");
int nameCount = 0;
// just count the number of names and save the last one you saw
String lastName = "";
while (tokenizer.hasMoreTokens()) {
lastName = tokenizer.nextToken();
nameCount++;
}
// At this point, nameCount is the number of sections of the domain
// and lastName is the last section.
// More than 2 sections is okay for everyone
if (nameCount > 2) return true;
// Less than 2 is bad for everyone
if (nameCount < 2) return false;
// Exactly two, you better match one of these 7 domain types
if (lastName.equals("com") || lastName.equals("edu") ||
lastName.equals("net") || lastName.equals("org") ||
lastName.equals("gov") || lastName.equals("mil") ||
lastName.equals("int")) return true;
// Nope, you fail - bad domain!
return false;
}
// Use the cookie string as originally set in the Set-cookie header
// field as the string value of this cookie. It is unique, and if you write
// this string to a file, you can completely regenerate this object from
// this string, so you can read the cookie back out of a file.
public String toString()
{
return cookieString;
}
}
The Cookie class is basically a holder for cookie data. The only methods in the Cookie class deal with converting strings into cookies and vice versa. The parseCookieValue method in the Cookie class implements a crucial part of the cookie protocol. It takes a string containing the settings for a cookie. The settings are of the form name=value and are separated by semicolons. The settings include the name of the cookie, the cookie's value, its expiration date, and the path name for the cookie.
The domain setting for a cookie specifies which hosts should receive the cookie. Whenever a URL in the cookie's domain is opened and the URL is in the cookie's path, the server for that URL is passed the cookie. For example, if you set the domain to mydomain.com and the path to /me/stuff, then the URL http://mydomain. com/me/stuff/mycgi will receive the cookie. An URL of http://mydomain.com/you/files would not receive the cookie, because the paths don't match.
There are some restrictions on the cookie's domain, too. If the domain ends in .com, .edu, .org, .net, .gov, .mil, or .int, you only need two components in the domain. In other words, you need one other name in addition to the ending. For example, mydomain.com is a valid domain.
If the domain ends with any other name, you must have at least three components in the domain. For example, mydomain.au would not be a valid cookie domain, but mydomain.outback.au would be valid.
Because cookies are supposed to be persistent, you need a class to manage your cookies-preferably by storing them in a file or a database. Listing 6.8 presents a portion of the CookieDatabase class that maintains a table of known cookies. The full source to the class is available on the CD-ROM that comes with this book. It has methods to store the table in a file and retrieve the table from a file. It can also examine an URL and return a string of cookie values for that URL.
The CookieDatabase class does not actually read cookies from a Web server or write them to the server. It simply keeps a table of known cookies. If presented with a host name and path name, the CookieDatabase class will determine which cookies are valid for that host name and path name and will return the appropriate cookie string.
The getCookieString method from the CookieDatabase class, shown in Listing 6.8, performs the matching between an URL and a cookie. It decides what cookies should be sent for a particular URL and creates a string containing all the cookie values that need to be sent.
Listing 6.8 getCookieString Method from CookieDatabase
// getCookieString does some rather ugly things. First, it finds all the
// cookies that are supposed to be sent for a particular URL. Then
// it sorts them by path length, sending the longest path first (that's
// what Netscape's specs say to do - I'm only following orders).
public static String getCookieString(URL destURL)
{
if (cookies == null) {
cookies = new Vector();
}
// sendCookies will hold all the cookies you need to send
Vector sendCookies = new Vector();
// currDate will be used to prune out expired cookies as we go along
Date currDate = new Date();
for (int i=0; i < cookies.size();) {
Cookie cookie = (Cookie) cookies.elementAt(i);
// See if the current cookie has expired. If so, remove it
if ((cookie.expires != null) && (currDate.after(
cookie.expires))) {
cookies.removeElementAt(i);
continue;
}
// You only increment i if you haven't removed the current element
i++;
// If this cookie's domain doesn't match the URL's host, go to the next one
if (!destURL.getHost().endsWith(cookie.domain)) {
continue;
}
// If the paths don't match, go to the next one
if (!destURL.getFile().startsWith(cookie.path)) {
continue;
}
// Okay, you've determined that the current cookie matches the URL, now
// add it to the sendCookies vector in the proper place (i.e. ensure
// that the vector goes from longest to shortest path).
int j;
for (j=0; j < sendCookies.size(); j++) {
Cookie currCookie = (Cookie) sendCookies.
elementAt(j);
// If this cookie's path is longer than the cookie[j], you should insert
// it at position j.
if (cookie.path.length() <
currCookie.path.length()) {
break;
}
}
// If j is less than the array size, j represents the insertion point
if (j < sendCookies.size()) {
sendCookies.insertElementAt(cookie, j);
// Otherwise, add the cookie to the end
} else {
sendCookies.addElement(cookie);
}
}
// Now that the sendCookies array is nicely initialized and sorted, create
// a string of name=value pairs for all the valid cookies
String cookieString = "";
Enumeration e = sendCookies.elements();
boolean firstCookie = true;
while (e.hasMoreElements()) {
Cookie cookie = (Cookie) e.nextElement();
if (!firstCookie) cookieString += "; ";
cookieString += cookie.name + "=" + cookie.value;
firstCookie = false;
}
// Return null if there are no valid cookies
if (cookieString.length() == 0) return null;
return cookieString;
}
Finally, Listing 6.9 shows you an example application that fetches a Web page that contains a cookie. Whenever the application runs, it loads its cookie table from a file called cookies.dat. After you run the program, you can look at the cookies.dat file. It is printable text. The program accesses a Web page called "Andy's Netscape HTTP Cookie Page" (http://www.illuminatus.com/cookie), which is a great resource for learning about cookies and seeing them in action.
Since the CookieDatabase class does not automatically look for
cookies in a response from a Web server, and does not automatically
send cookie data, you have to do that yourself. Cookies are sent
to the server in the header portion of an HTTP command.
| Note |
You can set only a few specific header values in the URL class, and the cookie string is not one of them. This means that you have to use sockets to perform a GET or POST that supports cookies. |
Whenever you open an URL, you can get the cookie string for the URL by calling getCookieString in the CookieDatabase class. When reading the response from the Web server, you must scan the header results for the Set-cookie command. Whenever you find this command, you pass the cookie string from the Set-cookie command to the addCookie method in the CookieDatabase class. The method will extract all the important information from the cookie string.
Listing 6.9 Source Code for TestCookie.java
import java.net.*;
import java.io.*;
// This application demonstrates the CookieDatabase and Cookie
// classes. It first loads the cookie database from cookies.dat,
// then it opens up Andy's Netscape HTTP Cookie Page, which happens
// to assign you a cookie.
// Because the Java URL classes do not let you set arbitrary header
// strings (GRR!!!), you have to do cookie stuff MANUALLY (double-GRR!!)
//
// Much of this code was taken from the example of doing a GET with
// raw sockets.
public class TestCookie extends Object
{
public static void main(String args[])
{
try {
CookieDatabase.loadCookies("cookies.dat");
} catch (IOException ignore) {
}
try {
// URL to Andy's Netscape HTTP Cookie Page, it's quite helpful
URL url = new URL("http://www.illuminatus.com/cookie");
int port = url.getPort();
if (port < 0) port = 80;
// Open a socket to the server
Socket socket = new Socket(url.getHost(), port);
// Create an output stream so you can write out the request header
DataOutputStream outStream = new DataOutputStream(
socket.getOutputStream());
// Write the GET command
outStream.writeBytes(
"GET "+url.getFile()+" HTTP/1.0\r\n");
// See if there are any valid cookies for this URL
String cookieString = CookieDatabase.
getCookieString(url);
// If so, write out a cookie header
if (cookieString != null) {
outStream.writeBytes("Cookie: "+
cookieString+"\r\n");
}
// Write out \r\n for the end of the header area
outStream.writeBytes("\r\n");
// Now read the response from the server
DataInputStream inStream = new DataInputStream(
socket.getInputStream());
String line;
// Read the header strings scanning for a set-cookie tag, which
// means you have to update the cookie database
while ((line = inStream.readLine()) != null) {
if (line.length() == 0) break;
// if you got a set-cookie, create a new cookie and add it to the database
if (line.toLowerCase().startsWith(
"set-cookie: ")) {
CookieDatabase.addCookie(
new Cookie(url,
line.substring(12)));
}
}
// Now that you've finished with the header, just dump out the
// contents of the page. This won't look too pretty, it's all pure
// HTML.
int ch;
while ((ch = inStream.read()) >= 0) {
System.out.print((char) ch);
}
// Save the cookie database for later use
CookieDatabase.saveCookies("cookies.dat");
} catch (Exception e) {
e.printStackTrace();
}
}
}